
True intelligence is not about memorizing video pixels in cyberspace. It is about internalizing the laws of the physical world through interaction.
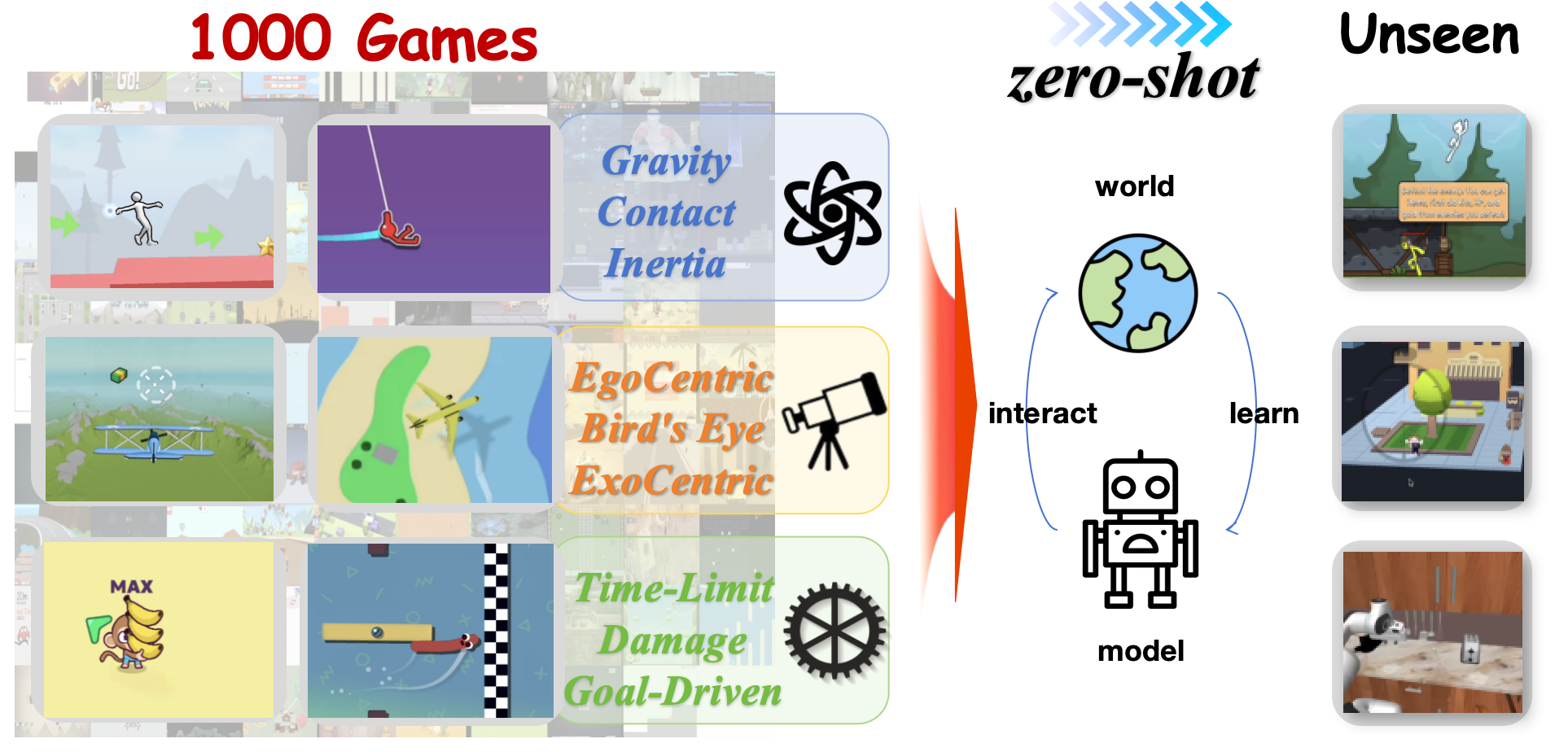
IPR-1 (Interactive Physical Reasoner) is an implicit physical-causal world model that can look ahead across 1,000+ physical worlds within one model. Following our long-term view on visual reasoning and physical reasoning, IPR-1 studies how interaction and scaling can lead to physical understanding, causal reasoning, and promising zero-shot transfer to real-world robotic control.
Background
How do humans come to understand the world? Not from labels alone. We learn physics and causality through interaction: as experience accumulates, prediction sharpens, reasoning stabilizes, and ability scales. Recent progress in Vision-Language Models (VLMs) and World Models has brought us closer to the promise of AGI, but their limits show up quickly in dynamic environments. Even a small viewpoint shift can break the illusion: many models tend to overfit to visual patterns, not the underlying physical and causal mechanisms.
The gap appears in different forms. VLM/VLA agents, whether in embodied domains, games, or other interactive settings, bring broad semantic priors and can reason over high-level goals, but they lack look-ahead and the predictive grounding required for interactive physical tasks. They can explain a scene, yet fail to anticipate what their own actions will cause. World Models face the opposite issue: they can imagine futures and generate realistic frames, but in practice they often imitate visual patterns rather than analyze physics and causality. In embodied environments, where contact and occlusion are routine, full-scene pixel prediction is often a noisy and indirect signal for choosing actions.
So can AI move beyond describing physics and learn to act within it? We argue that an agent should acquire human-like reasoning from interaction and keep improving with more experience. This is the motivation behind IPR-1 (Interactive Physical Reasoner). Following our long-term view on visual reasoning and physical reasoning, IPR-1 distills shared physical and causal mechanisms through interaction and scaling, rather than memorizing domain-specific appearances or action interfaces. To evaluate this paradigm at scale, we curate over 1,000 heterogeneous games as controllable physical worlds. On this large-scale physical reasoning benchmark, an 8B IPR-1 model outperforms much larger top models, including GPT-5, while also zero-shot transferring to novel environments.
Towards Animal-Like Intelligence
Given a complex video of physical interaction, strongest closed-source models can often produce a polished analysis. But once they are asked to actually play, their intelligence quickly looks fragile. On the path toward general embodied physical intelligence, four mainstream paradigms expose different bottlenecks:
Vision-Language Models / VLAs
- Strong at static semantic reasoning and high-level goal understanding.
- Lack mental look-ahead in dynamic interaction.
- Future consequences easily disconnect from action.
World Models
- Can generate visually convincing imagined futures.
- Often imitate visual patterns rather than analyze physics.
- Unstable under complex contact, occlusion, and interaction.
Imitation Learning
- Replays expert trajectories effectively in familiar settings.
- Does not necessarily internalize physical-causal mechanisms.
- Brittle when geometry, contact, or object layout shifts.
Reinforcement Learning
- Can solve single environments through massive trial and error.
- Often relies on task-specific shortcuts and dense rewards.
- Weak at zero-shot transfer to new physical worlds.
The Interactive Evaluation Pyramid
To move beyond the pseudo-intelligence that can appear in static language benchmarks, we discard traditional Q&A evaluation and build an interactive assessment pyramid inspired by Maslow's hierarchy. The goal is to strip away linguistic polish and measure physical competence through survival, exploration, and goal completion.
Utility
Tests whether an agent can use its physical understanding to complete explicit goals, such as collecting coins or reaching the destination.
Curiosity
Tests whether an agent can explore a broad physical space while maintaining basic survival.
Survival
Tests whether an agent has primitive physical intuition for avoiding harm and preserving itself, such as dodging monsters or not falling off cliffs.
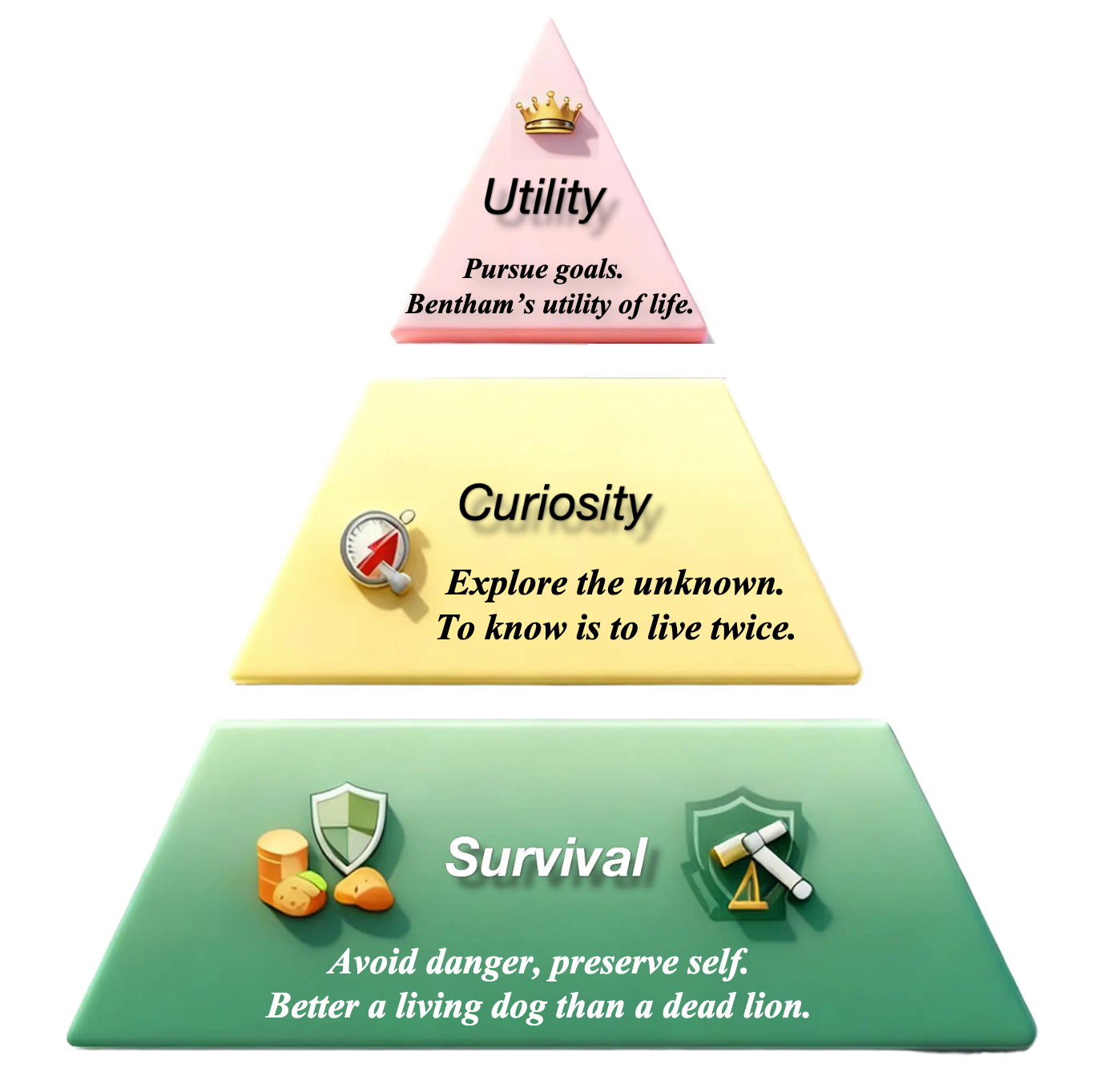
After evaluating classic models across 1,000+ game worlds, the conclusion is direct: massive parameters do not automatically produce physical intuition. Even trillion-parameter models can struggle on core Survival and Utility metrics, while the 8B IPR model succeeds by focusing on physics-centric interaction rather than brute-force memorization.
Sandtable Inference: Prediction-Reinforced Reasoning
Before acting, humans often run a sandtable simulation in the mind. IPR-1 reproduces this process by connecting the strategic reasoning of a VLM with the simulation capability of a World Model, forming a prediction-reasoning-reinforcement loop.
- Proposal: The VLM uses multimodal scene understanding to propose several high-potential candidate action sequences.
- Rollout & Scoring: The World Model acts as an implicit physical engine, rolling out candidate actions in imagination, predicting future states, and computing reward/value scores.
- Reinforcement: The system executes the best-scoring action, while future-aware feedback reinforces and improves the VLM policy.
Through this predict-reason-reinforce loop, static semantic knowledge becomes active physical interaction, giving the agent an intuition for future physical consequences.
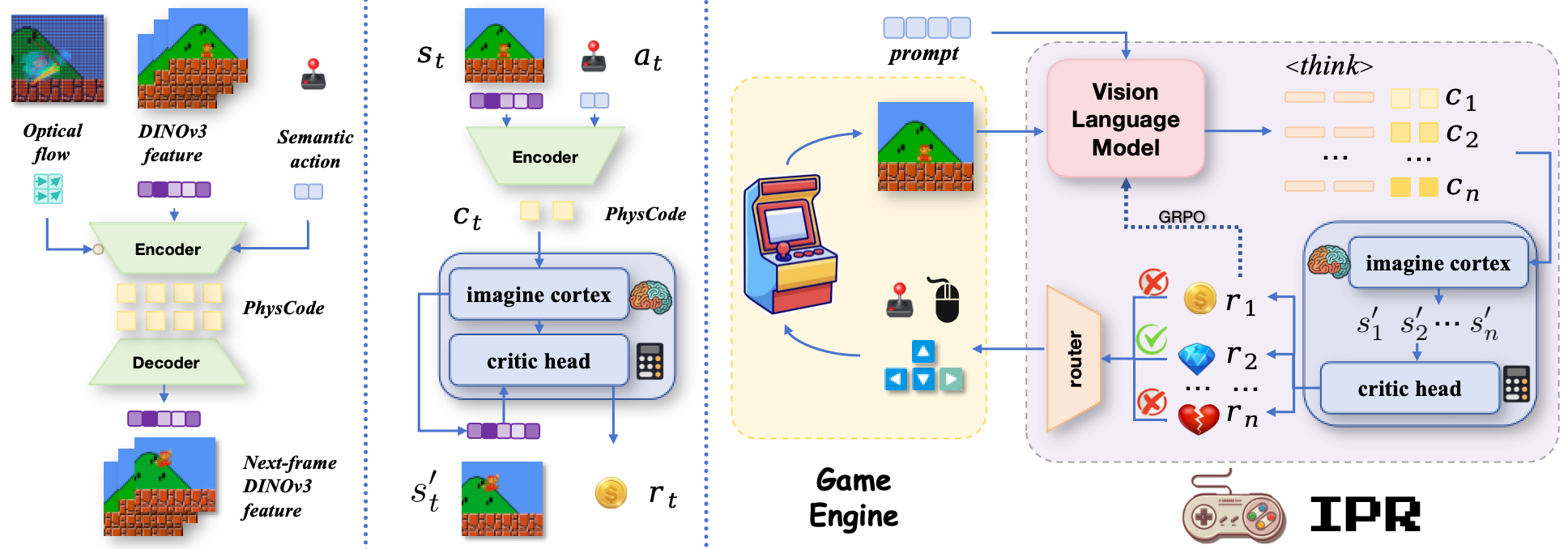
PhysCode: The Native Language of Physics
With sandtable inference in place, the next challenge is representation: how can a model grounded in text and pixels reason about actions, forces, and dynamics? We introduce PhysCode, a physics-centric action code that bridges VLM reasoning and world-model prediction by aligning semantic intent with physical dynamics.
PhysCode is pretrained from video clips, optical flow, and action semantics to form a discrete action vocabulary. Rather than modeling every visual detail, it filters out noisy background variation and anchors high-level intent to the low-level dynamics that actually govern interaction. The result is a shared action space where policy reasoning and forward prediction can reinforce each other.

Experiments: Understanding Physics in Game Worlds
We evaluate IPR-1 from four angles: whether PhysCode provides a transferable action space, how the model compares across 1,000+ games, whether physical reasoning scales with more interactive experience, and whether the agent can adapt when the rules of the environment change. Together, the results suggest that IPR-1 is learning reusable physical structure rather than memorizing game interfaces or control routines.
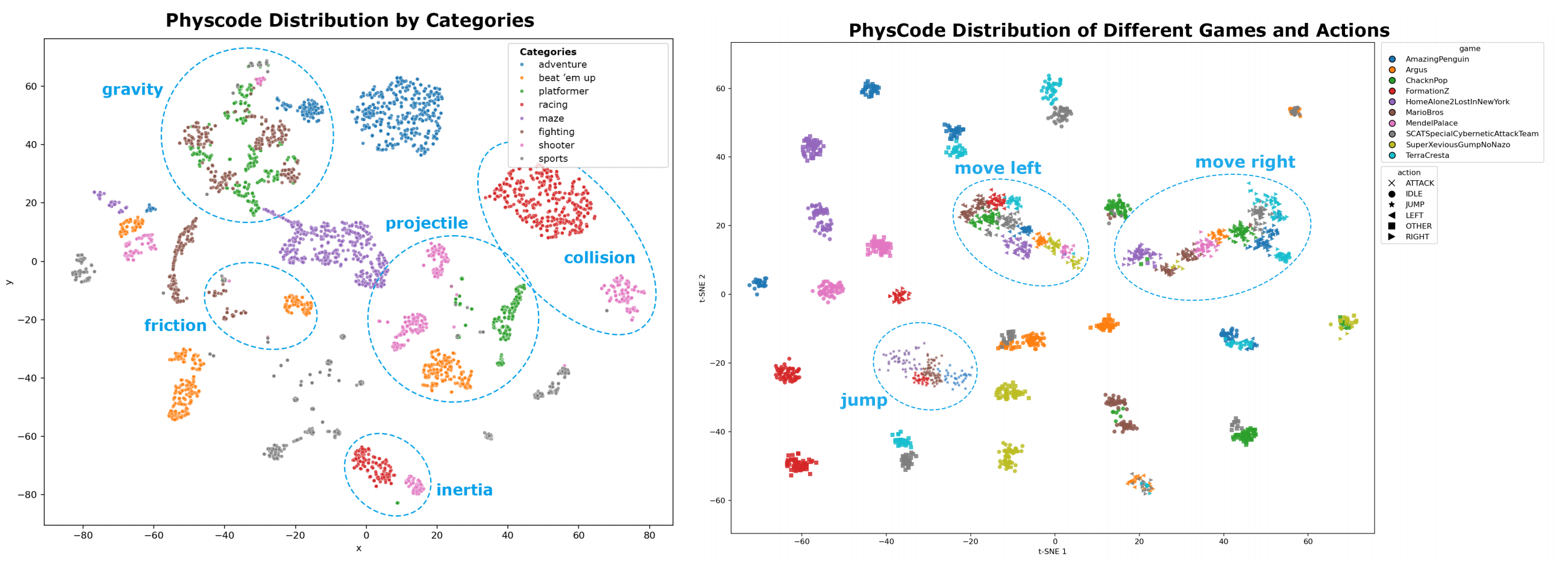
Does PhysCode Really Work?
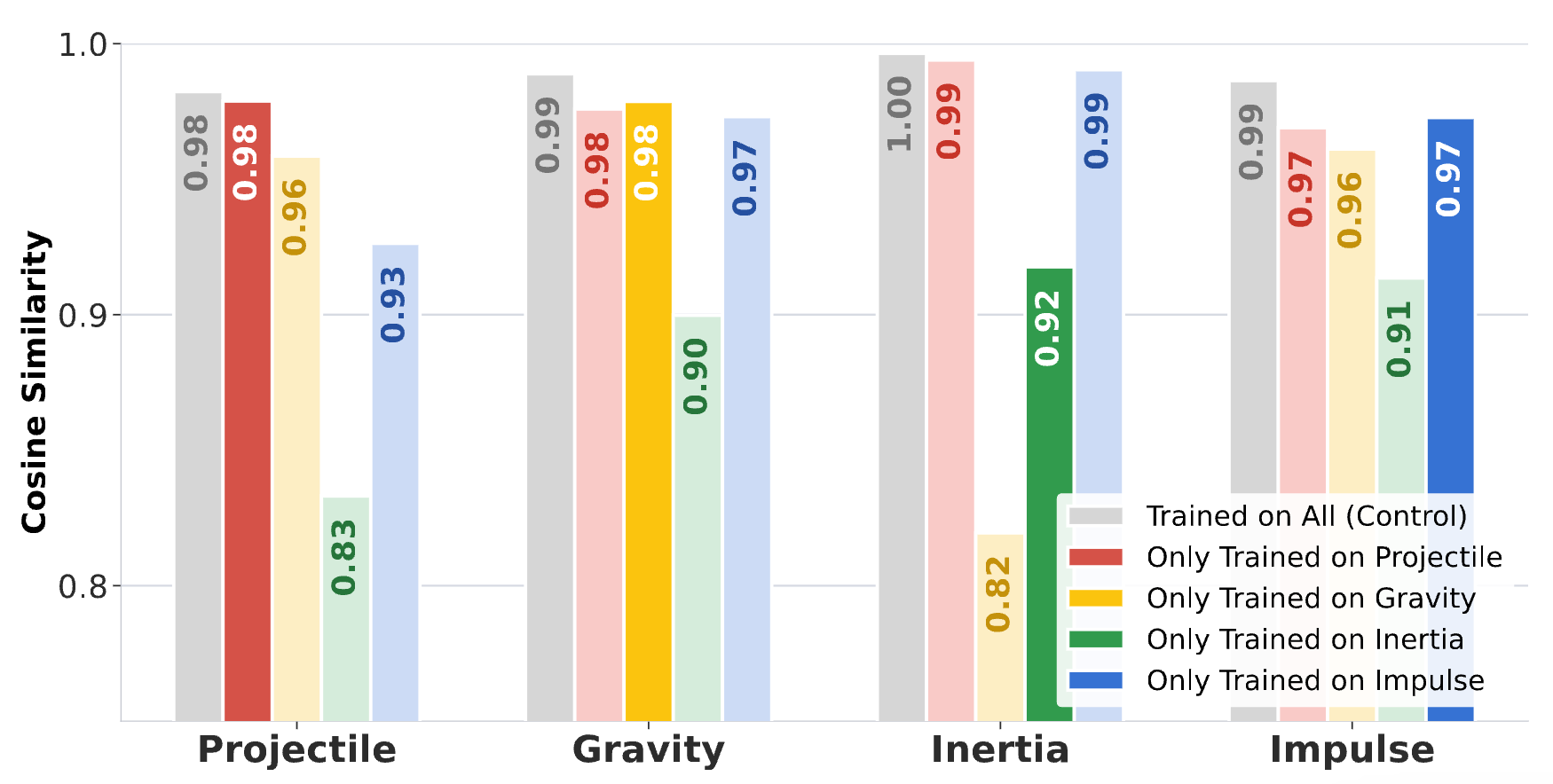
PhysCode defines actions by their underlying dynamics instead of raw keyboard commands, reducing ambiguity across games with different control interfaces. In blind tests on unseen games, PhysCode-based models transfer more reliably, suggesting that the representation captures reusable physical structure rather than game-specific controls. When games are grouped by core mechanisms such as gravity or inertia, models trained on one group perform better on unseen games governed by the same mechanism.
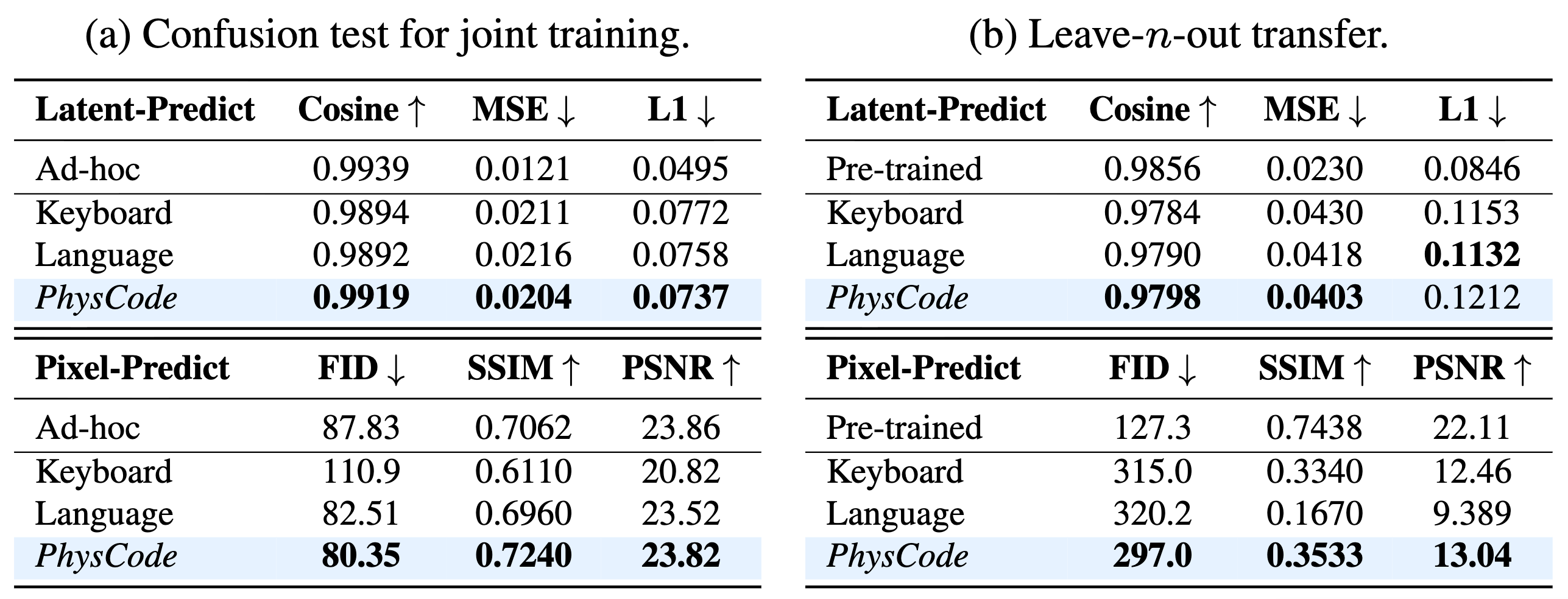
1000+ Game Worlds: Small Beats Large
On the 1000+ Game Worlds benchmark, a compact 8B IPR model combines semantic planning, physical prediction, and closed-loop reinforcement to outperform much larger static models across the core reasoning dimensions.
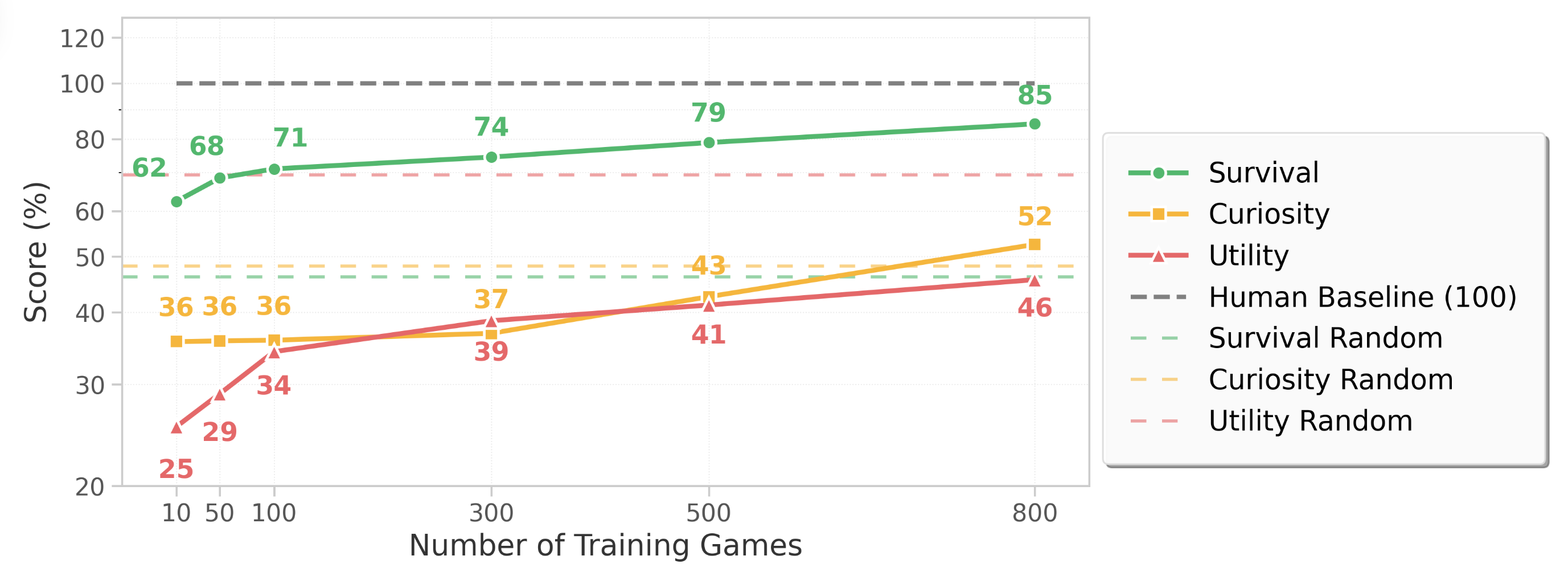
Scaling Laws of Physical Reasoning
Doing well in familiar environments is not enough; the real test is whether competence improves as experience broadens. As the number of pretraining games and interaction steps increases, IPR improves steadily across Survival, Curiosity, and Utility, revealing a clear scaling trend for physical reasoning.
Understanding Physics: Invariance Under Change
We further test physical understanding by changing environment parameters during gameplay, such as gravity strength or monster speed. Under this "hand of God" intervention, IPR-1 does not rigidly replay a memorized route. It adjusts jump timing, plans safer avoidance, and closes the loop between understanding physics, predicting future consequences, and choosing better actions.


Robotics Transfer
We further test whether physical and causal reasoning learned through interaction can transfer to robotic tasks. The videos below compare IPR against strong multimodal baselines in the same setting.




Zelda: Long-Horizon Physical Reasoning in a 3D World
We use Zelda as a 3D proxy for realistic simulation: it combines rich physical interaction, diverse objectives, and visually complex scenes that require planning beyond short-horizon reaction.
Commercial models often fail through delayed reactions, imprecise control, and weak future prediction. IPR improves by iteratively adding necessary physical and task conditions into the reasoning loop, eventually completing long-horizon tasks.
The same state can also admit multiple valid strategies. In an apple-picking task, IPR discovers different solutions under the same physical setup, showing its potential for open-ended embodied reasoning.
Conclusion
We believe IPR-1 points to a new scaling path for general physical foundation models and embodied intelligence. Instead of scaling only data, parameters, or static supervision, this path scales physics-centric interaction, allowing agents to build increasingly advanced physical reasoning abilities through experience.
We are now continuing along the IPR-1 direction to scale toward IPR-2, while evaluating its potential in real-world robotics and more complex physical environments.

Citation
@article{zhang2025ipr,
title={IPR-1: Interactive Physical Reasoner},
author={Zhang, Mingyu and Zhuo, Lifeng and Tan, Tianxi and Xie, Guocan and Nie, Xian and Li, Yan and Zhao, Renjie and He, Zizhu and Wang, Ziyu and Cai, Jiting and others},
journal={arXiv preprint arXiv:2511.15407},
year={2025}
}